Your backlog has 200+ items. Your team can ship maybe 10 this sprint. Picking the wrong ones means wasted effort, frustrated users, and missed revenue. That's why backlog prioritization techniques matter, they replace gut feelings with a repeatable process for deciding what gets built next.
But not every framework fits every team. Some work best when you have rich quantitative data; others shine when you're drowning in qualitative feedback from users. The trick is matching the right technique to your situation. At Koala Feedback, we help product teams collect and organize user feedback so that prioritization decisions are grounded in real demand, not internal assumptions.
This article breaks down six proven prioritization techniques for agile product teams. For each one, you'll get a clear explanation of how it works, when to use it, and where it falls short, so you can pick the method that actually moves the needle for your product.
User-feedback-driven prioritization means letting actual user demand shape your backlog order. Instead of relying on internal assumptions or stakeholder opinions, you use real votes, comments, and feature requests from your users to determine which backlog items deserve to move up.
This approach treats your users as the primary signal for what to build next. Tools like Koala Feedback give you a centralized feedback portal where users submit ideas, vote on existing requests, and comment on what matters to them. The volume and sentiment of those requests become your prioritization data.
When users vote on features, they reveal demand you can't see in analytics or support tickets alone.
Start by setting up a public feedback board where users can submit and upvote ideas. As requests come in, Koala Feedback automatically deduplicates and categorizes them so you're not manually sorting through hundreds of similar tickets. Then, during sprint or roadmap planning, sort by vote count and recency to surface the highest-demand items. Cross-reference the top requests against your strategic goals before committing anything to a sprint.
A simple workflow looks like this:
This technique works best for SaaS teams with an active user base who engage regularly with the product. If your users are vocal and you have enough request volume to spot patterns, feedback-driven prioritization gives you a strong, defensible foundation. It pairs well with other backlog prioritization techniques like RICE or MoSCoW, where you need a real demand signal before you start scoring.
The biggest risk is letting the loudest users dominate your roadmap. Power users or enterprise accounts often vote more than casual users, which skews your data toward niche needs. Always segment your feedback by user tier or revenue contribution so you're weighing demand from the right audience, not just the most active one.
RICE scoring gives your team a numerical way to rank backlog items by calculating a score for each one. The acronym stands for Reach, Impact, Confidence, and Effort, and the formula forces you to weigh the upside of a feature against the work required to build it.

RICE is a prioritization framework where you assign values to four factors and calculate a score: (Reach × Impact × Confidence) / Effort. A higher score means the item delivers more value relative to the resources it consumes, making it one of the most objective backlog prioritization techniques available.
RICE scores cut through opinion-based debates by giving every backlog item a number you can defend.
For each backlog item, estimate how many users it reaches in a given time period, rate the impact on a fixed scale (for example, 0.25 to 3), set your confidence as a percentage, and estimate effort in person-weeks. Then plug those values into the formula. Most teams do this in a shared spreadsheet so they can sort items by score and compare them directly.
RICE works well for mid-to-large teams that have enough usage data to make reasonable reach and impact estimates. It's particularly useful when you need to justify prioritization decisions to stakeholders or leadership.
The scores are only as reliable as your estimates. Teams often overestimate confidence on items they're excited about, which inflates scores. Calibrate your estimates against past results regularly to keep the framework honest.
MoSCoW is a structured categorization method that sorts backlog items into four buckets based on necessity. Unlike scoring-based backlog prioritization techniques, MoSCoW doesn't produce a ranked list with numbers. Instead, it forces your team to make clear, binary decisions about what the product absolutely needs versus what it can live without.
The acronym stands for Must have, Should have, Could have, and Won't have. Each item in your backlog gets assigned to one of these four categories. This framework originated in software development and remains widely used because it creates immediate clarity around delivery scope and stakeholder expectations.
Gather your team and stakeholders, then work through each backlog item together. Assign every item to a category based on user impact and delivery risk. Must-haves are non-negotiable for the current release. Could-haves are nice additions if time permits. Won't-haves get deferred explicitly, which prevents scope from creeping back in.
Labeling something a Won't have is just as valuable as identifying a Must have, it protects your team's capacity.
MoSCoW works best for fixed-deadline projects or release planning sessions where scope control matters. It's also useful when you need to align a diverse group of stakeholders quickly without requiring them to understand complex scoring formulas.
Teams tend to over-assign items to Must have, which defeats the purpose of the framework. Push back hard on any item that doesn't break the product if it's absent from the current release.
The Kano model helps you understand how different features affect user satisfaction, rather than treating all backlog items as equally valuable. It shifts the question from "what do users want?" to "how much will users care if we build or skip this?"
Developed by professor Noriaki Kano, this framework classifies features into three core categories: Basic needs (expected by default), Performance needs (the more you deliver, the more satisfied users are), and Delighters (unexpected features that create strong positive reactions). Unlike scoring-based backlog prioritization techniques, the Kano model focuses on the emotional response a feature generates, which reveals priorities that vote counts alone can miss.
Survey your users with paired questions for each feature: one asking how they'd feel if the feature existed, and one asking how they'd feel if it didn't. Map the responses to the Kano categories using a standard classification grid. Then prioritize Basic needs first, because missing them destroys satisfaction, followed by Performance needs that align with your growth goals.
Identifying Delighters early gives you a way to stand out from competitors without adding to your core roadmap.
This technique works best when you're planning a major release or evaluating a new product area where you're unsure how users will respond to different feature sets.
Kano requires running a proper survey, which takes time. Teams often skip the research and guess the categories, which undermines the entire framework. Invest in at least 20 to 30 user responses before drawing conclusions.
WSJF (Weighted Shortest Job First) is a prioritization formula from the Scaled Agile Framework (SAFe) that ranks backlog items by dividing the cost of delay by job duration. Instead of asking what's most valuable in general, it asks what's most valuable right now, given how long an item stays unshipped.

The formula scores each item as Cost of Delay / Job Size. Cost of Delay captures the business value you lose for every sprint the item sits unbuilt. It combines user and business value, time criticality, and risk reduction into a single number. Higher WSJF scores signal items where delay is expensive and execution is fast, making it one of the more data-driven backlog prioritization techniques available to larger teams.
Prioritizing by cost of delay shifts the question from "what's important?" to "what gets more expensive the longer we wait?"
For each backlog item, score the three cost of delay components using relative sizing, then divide by your effort estimate. Sort from highest to lowest and pull items from the top. The three components to score are:
WSJF works best for program-level planning in larger organizations running SAFe or similar scaled agile methods. It's particularly effective when time-sensitive factors like competitive threats or regulatory deadlines make delay costs concrete and measurable.
Teams often assign arbitrary scores to cost of delay components without grounding them in real business data. Tie your estimates to actual revenue or retention metrics wherever possible to keep your scores defensible.
Stack ranking is one of the most direct backlog prioritization techniques available. It forces your team to arrange every backlog item into a single ordered list from most to least important, with no ties allowed. The constraint of picking an absolute order is what gives this method its value.
Stack ranking requires you to place every item in your backlog into one definitive sequence. Unlike scoring frameworks, there's no formula involved. You simply decide whether item A outranks item B, work through your list, and produce a clear, unambiguous priority order your team can act on immediately.
Start with your full backlog and compare items head-to-head. Pick the most important item first, then find the second most important, and continue down the list. Some teams use a bracket-style comparison to make the process faster when the backlog contains many items.
The discipline of forced ranking surfaces real disagreements about priorities that scoring systems often paper over.
Stack ranking works best for small teams or early-stage products where the backlog is short enough to compare items directly. It's also useful when you need a fast decision without running a full scoring exercise.
The biggest issue is ranking fatigue on large backlogs. Comparing 150 items one-by-one becomes exhausting and leads to poor decisions near the bottom of the list. Limit stack ranking to your top 20 to 30 items to keep the process accurate and manageable.
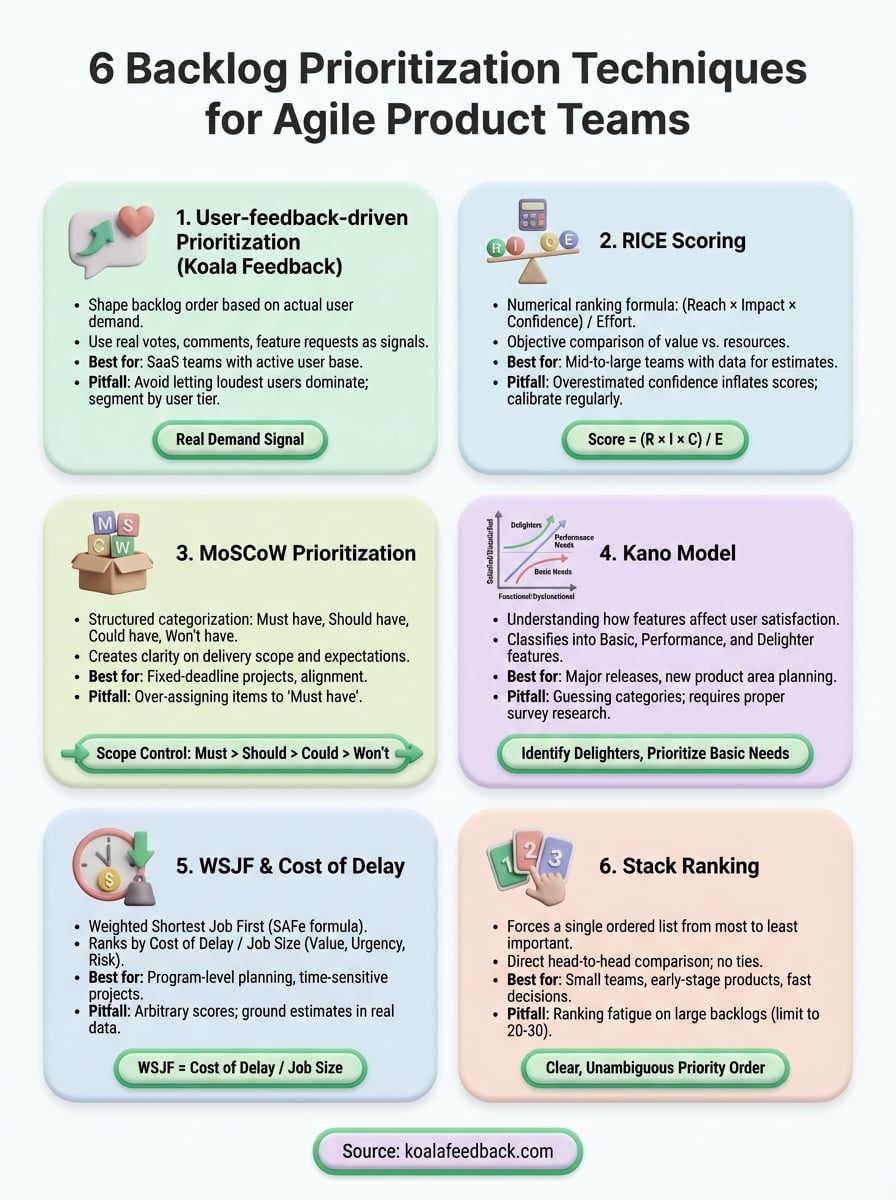
No single method wins every situation. The right starting point depends on where your product is today and what data you already have. If you have an active user base, start with feedback-driven prioritization to ground your decisions in real demand. If you need to justify choices to stakeholders or leadership, pair that with RICE scoring for a defensible numeric output.
For fixed deadlines or release scoping, MoSCoW brings fast alignment. For deep feature research, run a Kano survey. For large-scale program planning, WSJF connects your backlog to real business cost. And when you just need a quick answer, stack rank your top items.
Most teams combine two or three of these backlog prioritization techniques rather than committing to one. Start simple, build confidence, then layer in more structure as your process matures. Set up a feedback portal with Koala Feedback and give your prioritization decisions a foundation built on real user demand.

Start today and have your feedback portal up and running in minutes.
